Sistemas de Computação
Mestr. Integr. Engª.
Informática, 1º ano
2015/2016
Docente
responsável: A.J.Proença
Autoavaliação
Avaliação de desempenho
Ultima Modificação: 02 Fev 2020
|
|
A |
R |
B |
E |
|---|---|---|---|---|
|
Conhecimentos e competências específicas de Sistemas de Computação |
||||
|
- Identificar e descrever as
métricas que caracterizam o desempenho da execução de programas,
distinguir técnicas de optimização de desempenho dependentes e
independentes da máquina, descrever, aplicar e avaliar as técnicas de
desempenho independentes da máquina (as mais comuns), |
- - - |
Ö - - |
Ö Ö - |
Ö Ö Ö |
|
- Distinguir escalas de
tempo nos sistemas e técnicas de medição de desempenho, |
- - |
Ö - |
Ö Ö |
Ö Ö |
R1.
Comente as seguintes afirmações:
a) "Sempre que me pedem para melhorar o desempenho de uma dada aplicação (sem alterar o algoritmo) procedo da seguinte maneira e por esta ordem: (i) olho para o código e procuro todos os ciclos ("loops"), (ii) aplico todas as técnicas conhecidas de optimização de código, incluindo loop unroll e execução paralela de operações sobre elementos de arrays, (iii) e recomendo que o cliente troque o seu CPU por outro com frequência de clock superior"
b) "Quando se tenta optimizar o desempenho na execução de uma aplicação, a opção de loop unroll num ciclo com muitas iterações deve ser evitado, senão, ao desenrolar por completo o ciclo, arrisco-me a ficar com um pedaço de código muito grande que não cabe todo na cache, e portanto sou fortemente penalizado com excessivos acessos à memória com cache miss"
R/B1.
A seguinte função calcula a soma dos elementos
numa lista ligada:
int soma_lista(list_ptr ls)1
O código assembly que um compilador geraria para este ciclo, e respectiva conversão para operações do P6 (IA-32), teria o seguinte aspecto:
|
Instruções em assembly |
Operações da Execution Unit do P6 |
|
.L43: |
. |
Recordar que:
- a unidade de execução do P6 tem várias unidades funcionais, sendo apenas
algumas replicadas;
- a latênca dessas unidades não é igual para todas elas, e que algumas
permitem execução encadeada no seu interior;
- o P6 permite a execução de instruções fora de ordem e que pode, em cada
instante, enviar simultaneamente 3 instruções para a unidade de execução (i.e., é superescalar nível
3, ou em terminologia inglesa, 3-way superscalar).
a) Desenhe um diagrama que mostre a sequência de operações para as primeiras 3 iterações do ciclo (use um tipo de diagrama semelhante ao utilizado nos slides das aulas).
b) As medições efectuadas para este ciclo mostraram um valor de CPE de 4.00. Este valor está consistente com o diagrama desenhado na alínea anterior?
c) Considere agora que a arquitectura do P6 não era superescalar, i.e., em cada ciclo de clock apenas poderia ter início uma nova instrução na execution unit. O valor de CPE vai ser alterado? Redesenhe o diagrama com a sequência temporal de operações em 3 iterações e estime o novo valor de CPE.
d) Considere agora uma função ligeiramente diferente, que calcula o produto dos elementos em vez da soma. Sabendo que o produto tem uma latência 4 vezes superior à adição, o valor do CPE vai também aumentar? Continue a considerar a arquitectura do P6.
a) "Sempre que me pedem para melhorar o desempenho de uma dada aplicação (sem alterar o algoritmo) procedo da seguinte maneira e por esta ordem: (i) olho para o código e procuro todos os ciclos ("loops"), (ii) aplico todas as técnicas conhecidas de optimização de código, incluindo loop unroll e execução paralela de operações sobre elementos de arrays, (iii) e recomendo que o cliente troque o seu CPU por outro com frequência de clock superior"
Sugestão de resolução
Primeira questão a considerar é a ordem das acções a tomar: parece acertada neste caso, embora seja cedo para comentar se é suficiente ou não.
Segunda questão: cada uma das acções estará correcta e será adequada? Vamos analisar caso a caso:
(i) A código da aplicação poderá conter muitas funções e cada com muitos ciclos. Mas será que a utilização típica desta aplicação utiliza da mesma maneira todas as funções e ciclos? Algumas destas funções serão muito provavelmente para resolverem situações de excepção (e não a regra), pelo que o desempenho destas funções poderá não ser crítico. Outras funções apenas serão utilizadas uma vez (funções de inicialização de arrays, por exemplo) ou muito esporadicamente. A 1ª acção a tomar seria então tentar identificar as partes do código onde o CPU necessita de mais tempo para as executar - usando um analisador de perfis, ou profiler - seleccionando deste modo quais as partes do código onde valeria a pena investir tempo para melhorar o desempenho (tornando, eventualmente, o código menos legível, e dificultando a sua manutenção futura).
(ii) Uma vez identificadas as partes do código onde vale a pena investir na optimização, conviria começar por analisar o código gerado pelo compilador com um nível de optimização aceitável, para identificar quais as optimizações que o compilador já efectuou automaticamente, e quais as que não pode introduzir, e porquê. Só então, valerá a pena procurar introduzir modificações na codificação que permitam ultrapassar as limitações do compilador, garantindo contudo que o resultado final continua correcto. Mas atenção: há modificações que dependem da arquitectura do processador onde o código vai ser executado, fazendo com que algumas modificações melhorem o desempenho numas arquitecturas, mas piorem noutras. Estas modificações, designadas por optimizações dependentes da máquina (e que incluem as relacionadas com loop unroll e introdução de paralelismo), não deverão ser introduzidas de ânimo leve; deverão ser comprovadas/validadas na arquitectura alvo onde a aplicação irá ser executada.
(iii) Se após a introdução das melhorias referidas anteriormente o resultado final for ainda insatisfatório, então poderá valer a pena propor alterações à arquitectura do equipamento do cliente; mas se as melhorias introduzidas forem suficientes, não parece ser eticamente correcto justificar up-grades de equipamento com base em necessidade de melhoria do desempenho desta aplicação. E quanto a up-grades, a opção de melhoria da frequência do clock é apenas uma entre várias, e normalmente é a que menor impacto tem no desempenho; provavelmente mais crítico poderá ser analisar a quantidade de memória existente nos níveis superiores da hierarquia de memória e, se insuficientes, aumentar a quantidade de memória onde necessário. Mas um estudo sério para quantificar estas necessidades ultrapassa o âmbito desta disciplina...
Comente as seguintes afirmações:
a) ...
b) "Quando se tenta optimizar o desempenho na execução de uma aplicação, a opção de loop unroll num ciclo com muitas iterações deve ser evitado, senão, ao desenrolar por completo o ciclo, arrisco-me a ficar com um pedaço de código muito grande que não cabe todo na cache, e portanto sou fortemente penalizado com excessivos acessos à memória com cache miss"
Sugestão de resolução
Esta afirmação contém vários factos, uns correctos, outros não. A questão aqui é identificar onde estão as falhas no raciocínio exposto.
À primeira vista, não parece fazer sentido
excluir a hipótese de se usar o loop unroll para melhorar o desempenho...
A justificação apresentada - "arrisco-me
a ficar com um pedaço de código muito grande que não cabe todo na cache"
- tem lógica, mas parte de um pressuposto errado: o de que a operação de loop
unroll significa "desenrolar
por completo o ciclo".
O desenrolar de um ciclo não implica fazê-lo por completo, mas tão somente
diminuir o nº de iterações do ciclo; a simples duplicação das operações a
efectuar no interior de um ciclo, conduz a uma redução para metade do nº de
iterações do mesmo ciclo; e o triplicar das operações, uma redução para 1/3.
Assim, se se proceder por passos, é possível introduzir modificações
significativas sem se ser penalizado pelo facto de a totalidade do código do
ciclo não caber na cache.
Outros pb's surgiriam provavelmente antes de se colocar esta questão da cache,
como por ex. a insuficiência do nº de registos para permitir replicações das
operações no interior do ciclo, o que iria requerer o uso da stack em
memória (para armazenar resultados intermédios) e respectivas consequências em
tempos de execução mais longos.
E há ainda a considerar o facto de o desempenho máximo estar limitado à latência
das operações que são necessárias executar no interior de cada ciclo, pelo que,
se se conseguir obter um desempenho próximo desse máximo teórico sem desenrolar
o ciclo, é pouco provável que o desenrolar do ciclo contribua para melhorar
ainda mais o desempenho.
A última parte da afirmação, a de se ser "fortemente
penalizado com excessivos acessos à memória com cache miss"
está integralmente correcta. Com efeito, se não for possível colocar o código
todo do ciclo na cache, isso significaria que, de cada vez que se
executasse uma iteração do ciclo, iria ocorrer um ou vários cache misses
com as consequentes penalizações (cache penalties) devido à maior
latência no acesso ao nível mais baixo da hierarquia de memória.
int soma_lista(list_ptr ls)1
O código assembly que um compilador geraria para este ciclo, e respectiva conversão para operações do P6 (IA32), teria o seguinte aspecto:
|
Instruções em assembly |
Operações da Execution Unit do P6 |
|
.L43: |
|
Recordar que:
- a unidade de execução do P6 tem várias unidades funcionais, sendo apenas
algumas replicadas;
- a latênca dessas unidades não é igual para todas elas, e que algumas
permitem execução encadeada no seu interior;
- o P6 permite a execução de instruções fora de ordem e que pode, em cada
instante, enviar simultaneamente 3 instruções para a unidade de execução (i.e., é superescalar nível
3, ou em terminologia inglesa, 3-way superscalar).
a) Desenhe um diagrama que mostre a sequência de operações para as primeiras 3 iterações do ciclo (use um tipo de diagrama semelhante ao utilizado nos slides das aulas).
Analisemos a lista que foi apresentada no enunciado para "Recordar
".
Quais as implicações para a resolução deste exercício?
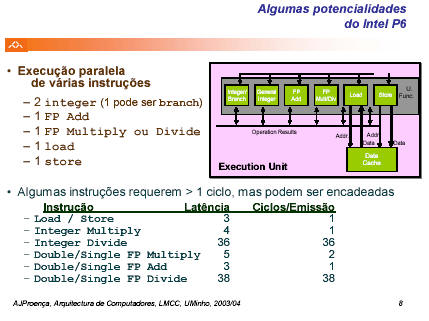
- se o P6 tem várias unidades funcionais que podem ser replicadas, importa
ver quais são, quantas réplicas existem (slide nº 8 de AvDes_2
replicado em baixo) e quais são as necessidades do código a executar: o código
tem 2 instruções aritméticas/lógicas sobre inteiros, 2 de load e 1 de
salto; o P6 tem 2 unidades aritméticas, sendo uma delas tb de saltos, e 1 de
load; mas a 1ª instrução produz dados para a 2ª, por isso estas não podem
estar em paralelo, mas devem ser executadas uma após outra; idênticas
dependências de dados encontram-se entre a instrução seguinte de load e o
teste, e entre o teste e o salto; e uma análise de dependências irá ter de ser
tb feita para as sucessivas iterações do ciclo;
- as únicas instruções neste código que têm
latência com duração superior a 1 ciclo de clock são as de load (3
ciclos, e encadeados, i.e., a unidade de load aceita processar novos
dados em cada ciclo de clock, embora necessite de 3 ciclos para concluir
a operação de load);
- se o P6 admite execução de instruções fora de ordem, então isto
significa que é possível iniciar a execução de uma instrução antes da anterior
ter terminado, ou, ainda melhor, antes de a anterior sequer ter iniciado; e
sendo superescalar nível 3 (e não nível 2 como referido, por lapso, nas aulas),
significa ainda que pode começar a execução simultânea de até 3 operações na
Execution Unit, desde que haja unidades funcionais disponíveis; analisando
agora o código deste pb: a 1ª instrução de load e a 1ª a iniciar; a 2ª
terá de aguardar que a 1ª termine; a 3ª, que não depende das anteriores, poderia
começar ao mesmo tempo que a 1ª, se houvesse 2 unidades de load; como não
há, e como a unidade de load está disponível no ciclo de clock
seguinte, é aí que começa; a 4ª só pode começar depois da 3ª terminar, e a 5ª
depois da 4ª; há aqui nitidamente apenas 2 conjuntos de instruções que podem ser
executados em paralelo (a cores diferentes na figura), embora ambos dependam da mesma variável no início do
ciclo de iteração:
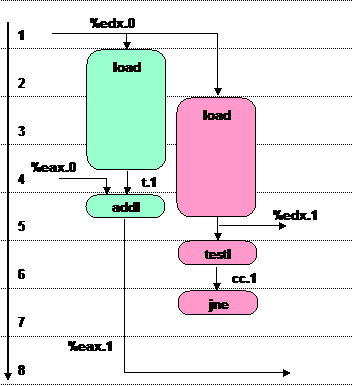
O diagrama representa a execução de um ciclo da iteração (excluindo a parte da busca e descodificação da instrução, que tb estão incluidos no pipeline global), ao longo de 7 ciclos de clock. De notar que o próximo ciclo da iteração apenas poderá iniciar 4 ciclos de clock após este ciclo de iteração ter iniciado (que é quando o novo apontador para o início da lista, em %edx, se torna disponível).
Se agora juntarmos os diagramas dos 3 primeiros ciclos da iteração, validando se em cada ciclo de clock todos os recursos necessários estão disponíveis, então teremos o seguinte diagrama em resposta ao solicitado na alínea:
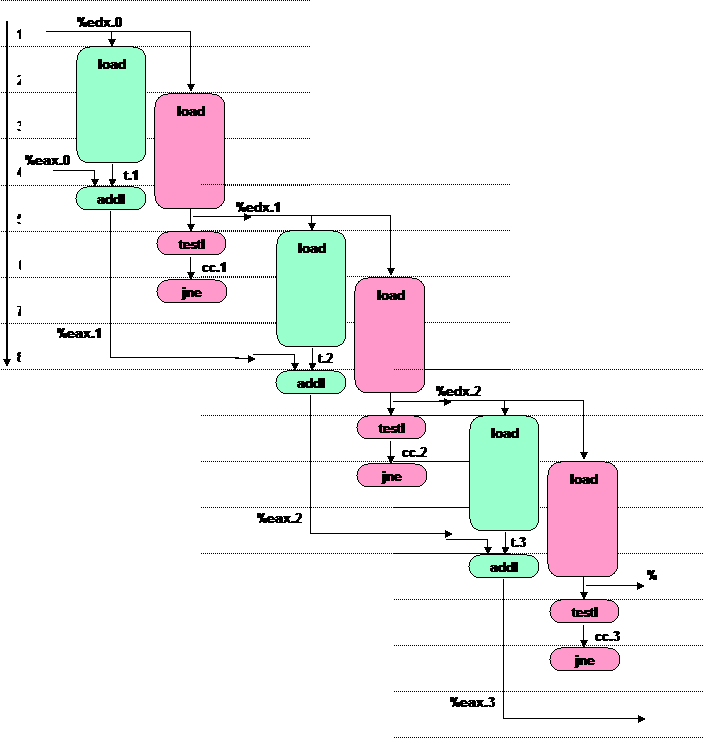
int soma_lista(list_ptr ls)1
a) ...
b) As medições efectuadas para este ciclo mostraram um valor de CPE de 4.00.
Este valor está consistente com o diagrama desenhado na alínea anterior?
De acordo com o diagrama e com o que ficou
escrito atrás, cada nova iteração apenas se pode iniciar após 4 ciclos de
clock, o que está consistente com o valor de CPE de 4.00.
Os factores que limitam o desempenho em cada iteração são (i) o facto de
a operação que carrega da memória o apontador para o próximo valor da lista
necessitar de 3 ciclos de clock, e (ii) ao qual se adiciona 1
ciclo de clock de espera, devido à incapacidade de o compilador verificar
que se trocasse a ordem de execução das 2 operações de load poderia
melhorar o desempenho global para um valor de CPE de 3.00.
Desafio para estudantes Excelentes: modificar o código em C para que a ordem de execução em assembly permita a optimização referida.
int soma_lista(list_ptr ls)1
a) ...
b) ...
c) Considere agora que a arquitectura do P6 não era superescalar, i.e., em cada
ciclo de clock apenas poderia ter início uma nova instrução na execution unit. O
valor de CPE vai ser alterado? Redesenhe o diagrama com a sequência temporal de operações
em 3 iterações e estime o novo valor de CPE.
A análise do diagrama em cima mostra que durante a 1ª iteração nenhum par de instruções começa no mesmo ciclo de clock; tal só acontece nos 2 primeiros ciclos de clock de cada iteração, por sobreposição com a iteração anterior. Isto significa que cada nova iteração terá de atrasar 2 ciclos de clock relativamente à iteração anterior, fazendo com que o valor de CPE suba para 6.00.
int soma_lista(list_ptr ls)1
a) ...
b) ...
c) ...
d) Considere agora uma função ligeiramente diferente, que calcula o produto dos
elementos em vez da soma. Sabendo que o produto tem uma latência 4 vezes
superior à adição, o valor do CPE vai também aumentar? Continue a considerar a
arquitectura do P6.
A análise do diagrama em cima mostra que se
substituirmos a operação de adição pela multiplicação com uma latência de 4
ciclos de clock, não vai haver qualquer alteração no desempenho da
execução de cada iteração, uma vez que o resultado da adição tinha sempre que
esperar 3 ciclos clock antes de ser utilizada.
Assim, o valor de CPE deverá manter-se em 4.00.