Arquitectura de Computadores
Notas de estudo
Alberto José Proença
1999/00
Nos capítulos anteriores completou-se a análise detalhada do instruction set de uma arquitectura RISC - MIPS V.1 com o estudo, a título de exemplo, da estrutura de 2 procedimentos - complementada por uma análise comparativa das abordagens em arquitecturas RISC e CISC (em sistemas de computação) e de arquitecturas para sistemas embebidos (inc. microcontroladores e DSPs).
Neste capítulo vai-se analisar um dos aspectos fundamentais da estrutura interna de um processador: como as operações aritméticas e lógicas funcionam no CPU e como podem ser implementadas em termos de circuitos digitais. Vai-se apresentar como é construído uma ALU de 32 bits a partir dos circuitos básicos and, or, inv e dum selector/multiplexador; com esta ALU será possível efectuar as operações aritméticas e lógicas básicas presentes no MIPS (add, sub, and, or, slt) e ainda apoiar e execução de instruções de salto condicional (beq).
Analisa-se de seguida o funcionamento das operações multiplicação e divisão de inteiros e faz-se uma introdução aos algoritmos de operações em vírgula flutuante.
Este assunto é tratado dum modo exaustivo no texto de apoio (ver 4.1 a 4.8). As figuras referenciadas ao longo deste capítulo são as usadas na íntegra no livro recomendado, e estão disponíveis aqui em formato WMF compactado (221K para todas as figuras do cap. 4).
As operações aritméticas com inteiros nas processadores actuais fazem-se assumindo que os valores negativos estão representados em complemento para 2 (objecto de revisão em aulas anteriores, e minimamente documentado no Anexo A). Apenas de salientar que ao estender um nº com poucos bits para um com 32 bits convém não esquecer de fazer a extensão do bit do sinal!
Um dos aspectos interessantes na utilização da representação em complemento para 2 para inteiros negativos é o facto desta representação permitir a utilização do mesmo hardware na implementação das operações de soma ou subtracção, simplesmente através da implementação da subtracção como adição com nº negativo, em complemento para 2.
Ao representar valores infinitos com um nº finito de bits, o CPU corre o risco de efectuar operações cujos resultados poderão necessitar de um maior nº de bits que aqueles disponibilizados, i.e., pode haver a ocorrência de overflow . No caso da adição e subtracção esta situação pode ocorrer sempre que o resultado duma operação vai alterar duma maneira incorrecta o bit do sinal; por outras palavras, sempre que :
Para resolver estas situações, o hardware do MIPS tem mecanismos que permitem detectar esta ocorrência e causar uma interrupção da execução do programa que causou o overflow. Este assunto será analisado com mais detalhe quando se abordar o tema do tratamento das excepções.
Existem, no entanto, situações em que o utilizador não pretende activar qualquer mecanismo de interrupção, por considerar perfeitamente aceitável a ocorrência deste tipo de overflow, em particular quando se trate de instruções que lidem com endereços (valores sem sinal). Prevendo estes casos, o instruction set do MIPS disponibiliza instruções de adição e subtracção que não activem a interrupção por ocorrência de overflow, usando o sufixo de unsigned na designação da operação (addu, addiu, subu).
Já foi feita referência às operações lógicas, mas houve dois aspectos que ainda não foram devidamente tratados: as operações de deslocamento lógico e aritmético de bits e a utilização de máscaras para selecção e montagem de sequências de bits.
O formato de instrução do tipo R contém um campo designado de shamnt (de shift amount ), o qual pode ser utilizado nas instruções de deslocamento de bits para especificar o nº de bits a deslocar nas instruções de shift.. Neste tipo de instruções também se especifica se o deslocamento é para a esquerda ou para a direita, e qual o valor dos bits a introduzir numa das extremidades: se zero (deslocamento lógico, sll, srl ) se o bit do sinal quando o deslocamento é para a direita (deslocamento aritmético, sra ). Existem ainda instruções onde é possível especificar um valor variável para o nº de bits a deslocar logicamente (sllv, srlv, srav ), através do registo rs .
Quando se referiu anteriormente a existência das instruções lógicas and, or, não se avançou quanto à utilidade deste tipo de instruções: estas são essencialmente usadas na operação com máscaras. Podemos considerar uma máscara como sendo uma palavra constituída por bits "transparentes" e por bits "opacos".
No caso de uma operação and (produto lógico) a máscara é usada para seleccionar um conjunto de bits duma palavra - os que forem especificados pelos bits "transparentes" da máscara, i.e., por elementos neutros do produto lógico (1) - colocando os restantes bits a 0 (que é o elemento absorvente do produto lógico, e que constituem a parte "opaca" da máscara).
No caso de uma operação or (soma lógica) a máscara é usada como molde para colocar um conjunto de bits numa palavra - a parte "opaca" da máscara, assumindo que a palavra original tem esse bits já a zero - e deixando inalterados os restantes bits da palavra - usando a parte "transparente" da máscara, constituída pelos elementos neutros da soma lógica (0). Um exemplo de utilização desta instrução foi já referido anteriormente: na colocação de um valor imediato de 32 bits num registo, com as instruções lui (que deixa os 16 bits menos significativos a zero) e ori (o valor imediato de 16 bits é a parte "opaca").
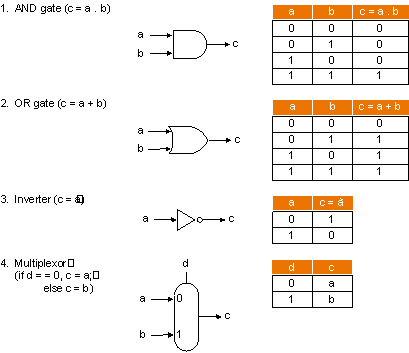
Em qualquer sistema digital é possível identificar um conjunto de blocos constituintes básicos, a partir dos quais é possível implementar uma ALU. Estes blocos implementam as seguintes operações lógicas (ver figura): soma (or gate ), produto (and gate ), negação (inversor) e selecção (multiplexador).
A secção 4.5 expõe com detalhe - e acompanhada de figuras explicativas - a construção de uma ALU com 32-bits (a partir de ALU's de 1-bit) que permite implementar as operações lógicas e aritméticas existentes no MIPS. A sequência de exposição desta construção começa com uma ALU de 1-bit:
continuando depois na construção de uma ALU de 32-bits construída com 32 ALU's de 1-bit. De seguida completa-se a ALU de 1-bit de modo a implementar as operações requeridas pelo MIPS:
apresentando no final uma imagem, ainda incompleta, de uma ALU de 32-bits. Esta imagem é completada com o suporte à execução de instruções condicionais, seguida da apresentação do símbolo universal para a ALU completa para o MIPS, com a respectiva tabela de valores para os sinais que especificam a operação a efectuar.
Esta implementação de uma ALU de 32-bits é bastante penalizada em termos de performance : o tempo necessário para efectuar uma operação de 32-bits é pelo menos 32 vezes superior ao tempo de execução de uma com 1-bit; isto deve-se à propagação do sinal de carry através de todas as ALU's, necessitando de passar em pelo menos 2 gates em cada ALU para que um novo valor de carry out seja gerado a partir do valor de carry in. . A este tipo de propagação "ondulada" de um sinal de carry designa-se por ripple carry. Como alternativa que requer bastante mais recursos de hardware, é possível calcular o valor de qualquer carry in à entrada de cada ALU - levando apenas o tempo de percorrer 2 gates - como que antecipando o valor que viria da ALU operando sobre o bit imediatamente menos significativo; a este tipo de implementação designa-se por carry lookahead, e é modo usado em qualquer processador disponível comercialmente.
À semelhança da metodologia adoptada na semana anterior - analisar o princípio básico de funcionamento e respectiva implementação, sem ter a preocupação da eficiência na execução - os algoritmos a analisar para efectuarem a multiplicação de inteiros têm como objectivo mostrar uma forma de implementação conceptualmente simples, embora pouco eficiente e como tal não adoptada nos processadores comerciais.
A operação de multiplicação de inteiros positivos em binário pode ser implementada simplesmente por sucessivas somas e deslocamentos de bits, do mesmo modo que se fazia na primária (quando o multiplicador tinha apenas zeros e uns). O valor a somar em cada um dos passos será de 0 ou o valor do multiplicando, consoante o dígito que se está a analisar do multiplicador seja 0 ou 1. Relembra-se ainda que numa operação de um multiplicando de n-bits com um multiplicador de m-bits, obtém-se um produto com n + m bits.
A implementação directa deste algoritmo no hardware vem representada na fig.4.20. Contudo esta proposta necessita de uma ALU de 64 bits para somar valores de 32 bits de cada vez... É possível melhorar esta implementação se atentarmos melhor ao modo como os cálculos são efectuados, e aplicarmos a operação de deslocamento ao resultado que vai sendo construído no registo com o produto, conforme exemplificado na fig.4.24. A fase seguinte de optimização da implementação vem ilustrada na fig.4.26.
O algoritmo analisado funciona apenas com valores positivos. Existem no entanto algoritmos para operar com valores negativos, e a secção 4.6 descreve com clareza e detalhe um desses: o algoritmo de Booth.
A terminar este assunto sobre multiplicação de inteiros, é possível ainda demonstrar que a multiplicação por potências de 2 pode ser implementada com instruções de deslocamento de bits para a esquerda; esta opção é normalmente a escolhida por compiladores, pois na maioria dos processadores o tempo de execução de uma instrução de deslocamento é inferior ao do de uma multiplicação.
Uma análise idêntica pode ser feita relativamente à operação de divisão de inteiros em binário em que esta operação pode também ser implementada com deslocamentos para a direita e subtracções sucessivas. A secção 4.7 descreve os algoritmos que poderão ser usados numa primeira abordagem (algoritmos claros mas pouco eficientes) e apresenta, à semelhança com o já feito relativamente à multiplicação, diversos diagramas com implementações sucessivamente melhoradas. A fig. 4.38 mostra a versão final, na qual é claramente visível que o algoritmo descrito permite partilhar hardware com a multiplicação.
A representação de valores em vírgula flutuante de acordo com a norma IEEE 754 foi objecto de aula prática numa sessão introdutória ao módulo de Arquitectura de Computadores. Para relembrar esse assunto, reproduz-se aqui de novo essas notas de estudo.
A norma IEEE 754 define com clareza a representação de valores normalizados e desnormalizados, bem como a representação de valores externos ao intervalo permitido com a notação normalizada, permitindo uma maior compatibilidade ao nível dos dados no porte de aplicações entre sistemas que adoptem a mesma norma. De momento todos os microprocessadores disponíveis comercialmente com unidades de fp suportam a norma IEEE 754 no que diz respeito aos valores de 32 bits. Aspectos relevantes na norma IEEE 754:
A norma IEEE 754 contempla ainda a representação de valores em fp que necessitem de maior intervalo de representação e/ou melhor precisão, por várias maneiras. A mais adoptada pelos fabricantes utiliza o dobro do nº de bits, 64, pelo que é também conhecida pela representação em precisão dupla, enquanto a representação por 32 bits se designa por precisão simples. Para precisão dupla, a norma especifica, entre outros aspectos, que o expoente será representado por 11 bits e a parte fraccionária por 52 bits.
As operações de adição e subtracção em vírgula flutuante requerem um algoritmo de execução bem mais complexo, uma vez que os valores em fp se encontram codificados e compactados sempre que são armazenados na memória (ou em registos). O 1º passo desse algoritmo consiste normalmente na identificação da operação que efectivamente se vai realizar - com base na operação indicada e nos sinais dos operandos - seguida da respectiva operação. A secção 4.8 descreve este algoritmo.
Uma vez identificada a operação efectiva, a apresentação do algoritmo para a adição/subtracção efectiva que foi efectuada na aula usou como exemplo a realização de várias operações decimais com valores em fp, e limitando a representação desses valores (3 dígitos para a mantissa, 1 para o expoente). Deste modo foi possível sensibilizar a audiência para os diversos passos que constituem o algoritmo:
Foi o seguinte o exemplo apresentado: dados os seguintes valores
identifique o algoritmo que permita efectuar correctamente as seguintes operações
A+B= ? A'+B= ? A''+B= ? A'''+B'= ?
O diagrama de blocos de uma unidade de vírgula flutuante (FPU) foi então apresentado (fig 4.42), tendo a sua estrutura sido descrita de modo idêntico ao da legenda dessa figura.