Arquitectura de Computadores
Alberto José Proença
1997/98
EM CONSTRUÇÃO...
Capítulos | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
Actividades paralelas em arquitecturas MIMD
Analisou-se no capítulo anterior a realização de actividades paralelas na ilusão de que o sistema para o qual se está a programar tem um comportamento sequencial. Neste capítulo vão-se analisar os sistemas que suportam paralelismo de actividades/processos, quer quando as suas variáveis partilham um mesmo espaço de endereçamento, quer ainda quando as actividades/processos estão disjuntos e apenas comunicam explicitamente por mensagens. O tratamento do paralelismo com partilha de variáveis vem tratado em 9.3 a 9.5, sendo o tema de coerência de caches em multiprocessadores coberto ainda de maneira interessante em Stallings; o paralelismo por comunicação de mensagens vem tratado em 9.6 e 9.7, podendo-se encontrar referências às topologias de interligação em qualquer dos outros livros sugeridos.
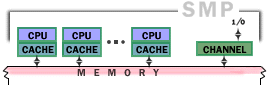
Topologia de interligação mais comum:
barramento(s) partilhado(s)SMP - Symmetric Multi-Processing, com uma memória global
(em http://www.dg.com/numaliine/)
NUMA - Non-Uniform Memory Access, com memória distribuida
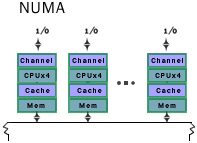
ccNUMA - Cache Coherent Non-Uniform Memory Access
Modelo de programação mais adequado:
- transferência de informação entre processos:
por variáveis globais, com partilha do espaço de endereçamento
- sincronização de actividades entre processos:
para controlo no acesso a recursos partilhados
para manutenção da ordem de execução (barrier instructions)
Técnicas de controlo no acesso a recursos partilhados:
- com semáforos, usando instruções atómicas
- usando monitores
- com regiões críticas condicionais
- ...
Coerência de informação nas caches
- estratégias:
Write invalidate
Write update
- protocolos:
Snoopy protocols adequado para topologias de interligação que suportam broadcast
Directory protocols adequado para arquitecturas MPP,
com topologias de interligação que não suportam broadcast
Análise dum protocolo snoopy : MESI (write invalidate)
- estados num protocolo MESI:
ModifiedExclusive
Shared (ex, Pentium, PowerPC, ...)
Invalid
- acções/transições:
·
RH Read Hit- não há transição, apenas leitura do ítem
·
RM Read Miss- mais nenhum processo tem cópia da linha; lê da memória e I -> E
- há um processo com uma cópia limpa em E,
que assinala aos outros com SHR Snoopy Hit on Read e transita de E -> S;
o processo inicial lê a linha e I -> S
- há um ou mais processos com cópia(s) limpa(s) em S,
que assinala(m) aos outros com SHR Snoopy Hit on Read ;
o processo inicial lê a linha e transita de I -> S
- há um processo com cópia modificada da linha em M,
que assinala o processo inicial para tentar de novo, com SHW Snoopy Hit on Write ,
escreve essa linha na memória (copy back) e transita de M -> S;
o processo inicial tenta de novo até se encontrar num dos outros casos
·
WH Write Hit- se o seu estado for M, apenas escreve no bloco
- se o seu estado for E, escreve no bloco e transita de E -> M
- se o seu estado for S, obtém primeiro a exclusividade no no acesso e...
fig 16.6 de Stallings
- acesso exclusivo à memória
fig 9.8
fig 9.9
E
strutura e comportamento do sistema de comunicações- as entidades comunicantes são processos
- as interfaces de comunicação entre processos são portas
- as mensagens circulam em paths
- os paths são uni-direccionais e ponto-a-ponto
- as seguintes ilusões são normalmente aceites:
- o envio/recepção de mensagens respeita a ordem
- as mensagens não são modificadas/perdidas no path
- o transporte de mensagens é limitado no tempo
- existem instruções específicas para a interacção entre processos, mensagens e as portas associadas
- actividades básicas ao nível do programa:
- envio/recepção de mensagens (send, receive)
- barreiras de sincronização (sync barriers)
I
ntervenientes num sistema de comunicação por mensagens- os módulos fonte e/ou destino, responsáveis por:
- computação (execução dos processos do utilizador e do SO)
- comunicação (execução dos protocolos de comunicação)
- os comutadores/encaminhadores (switches) - rede de interligação
Realização dos módulos fonte e/ou destino
- computação/comunicação partilhada no mesmo processador:
- requer mecanismos rápidos de sinalização inter-processadores (mensagens curtas e/ou barreiras de sinc)
- técnicas eficientes de comutação de contexto (computação/comunicação)
- computação/comunicação alocados a processadores distintos
- utilização:
- entre processadores
- entre processadores e módulos de memória
- entre nodos de proc-mem
- tipos de topologias:
- redes estáticas
- redes dinâmicas
- parâmetros que caracterizam as topologias:
- diâmetro da rede (influência pode ser min com wormhole routing)
- grau de conectividade por nodo (node degree)
- bisecção do canal na rede
- simetria
- funções de encaminhamento de dados:
- permuta (1-para-1) -> perfect shuffle, hipercubo
- difusão (1-para-todos)
- multi-difusão (muitos-para-muitos)
- análise de exemplos
fig 9.17
fig diversas de Hwang